JOIN/SIGN UP
Already a Member? |
GET INVOLVED
Understanding and Engaging in COVESA Expert Groups & Projects |
COLLABORATIVE PROJECTS
HISTORICAL
SDV Telemetry Project |
Already a Member? |
Understanding and Engaging in COVESA Expert Groups & Projects |
SDV Telemetry Project |
We use cookies on this site to enhance your user experience. By using this site, you are giving your consent for us to set cookies. |
So far, the data modeling activities in COVESA have been primarily centered on the continuous development and maintenance of the Vehicle Signal Specification (VSS) and the tools that parse VSS into different formats. In the current setup, there is no clear description of what requirements (i.e., functional and non-functional) are driving the design of the data model. It seems that the primary purpose of VSS is to serve as a naming convention for the properties of the vehicle. Nevertheless, there is little attention given to the separation of concerns:

The figure above shows how VSS modeling belongs to the conceptual area. To use the specification described in VSS (i.e., a "vspec" file), one has to parse it into a specific format (e.g., JSON) by using the VSS tools. The tools are the mechanism that makes the VSS data model usable in the application area. From the practical point of view, the application area needs a specific schema that determines the structure in which the data is to be stored. In this context, we mean long-term storage (e.g., a database) or short-term storage (RAM and variables' allocation during application execution).
In the current setup, the whole data model is taken one-to-one and parsed as the schema for the application area. Then, it is up to the specific implementation to use custom mechanisms to ignore the overhead when only some concepts defined in the data model are required or used. Although this aspect has shown no significant limitation until now, it becomes relevant when multiple domains are involved. Therefore, with the increasing interest in adding other domains apart from vehicle-specific data, it is crucial to define a data modeling strategy that can scale beyond tree hierarchies and vehicle-specific data.
One may argue that, with the current setup, it is also possible to describe a customised shorter spec file or use functions (e.g., overlays) to define the specification that matches the needs of the application area. Although possible, that implies creating disparate data models. Ideally, the concepts should be modelled only once in the conceptual area to serve as a controlled vocabulary. Then, an arbitrary selection of the concepts and some modifications to the constraints (e.g., min, max, etc.) can deliver the schema needed in specific use-cases, without affecting the standard definition of the concepts. Hence, the following section propose a few specific tasks to improve the data modeling workflow.
The idea is to define the data modelling workflow for COVESA in terms of the conceptual area (i.e., development and maintenance of the controlled vocabulary) and the application area (i.e., tools that construct a usable schema out of the data models for a particular use case).
In the conceptual area, there should be a clear step-by-step guide on how to work with two different levels of expressiveness. This consideration is needed because a tree hierarchical model alone (what VSS has been so far) is not the best model type to handle some upcoming needs, such as data integration. Hence, the model might be selected depending on the user needs.
(less expressive) Tree hierarchical model, good for:
Information classification according to a given criteria (e.g., taxonomy, meronomy, custom tree.)
Naming convention following a dotted notation (i.e., concatenation of the branches)
(more expressive) Ontology, good for:
Data integration
Concepts re usability
Reasoning
Multiple hierarchies
Knowledge representation
Regardless of the level of expressiveness selected by the end user, the data models developed and maintained by COVESA should use a common standard data exchange format. This standard representation of the data models will facilitate the transition from and inter operability between trees and ontologies.
As reported by experienced data modellers [R1], the current preferred data exchange format for tree-like models is RDF and SKOS standards. However, the current VSS tree is published with a custom YAML `vspec` file that requires the tooling to parse it.
Luckily, the RDF data model is also the foundation for the Web Ontology Language (OWL). Hence, there is a good opportunity here to harmonise the activities by using a common data model and vocabulary.
In the application area, the tools have to provide a mechanism to "cherry pick" (i.e., to arbitrary select) concepts of interest from one or multiple domains, including the context and pointers to the uniquely identified definition of the concepts.
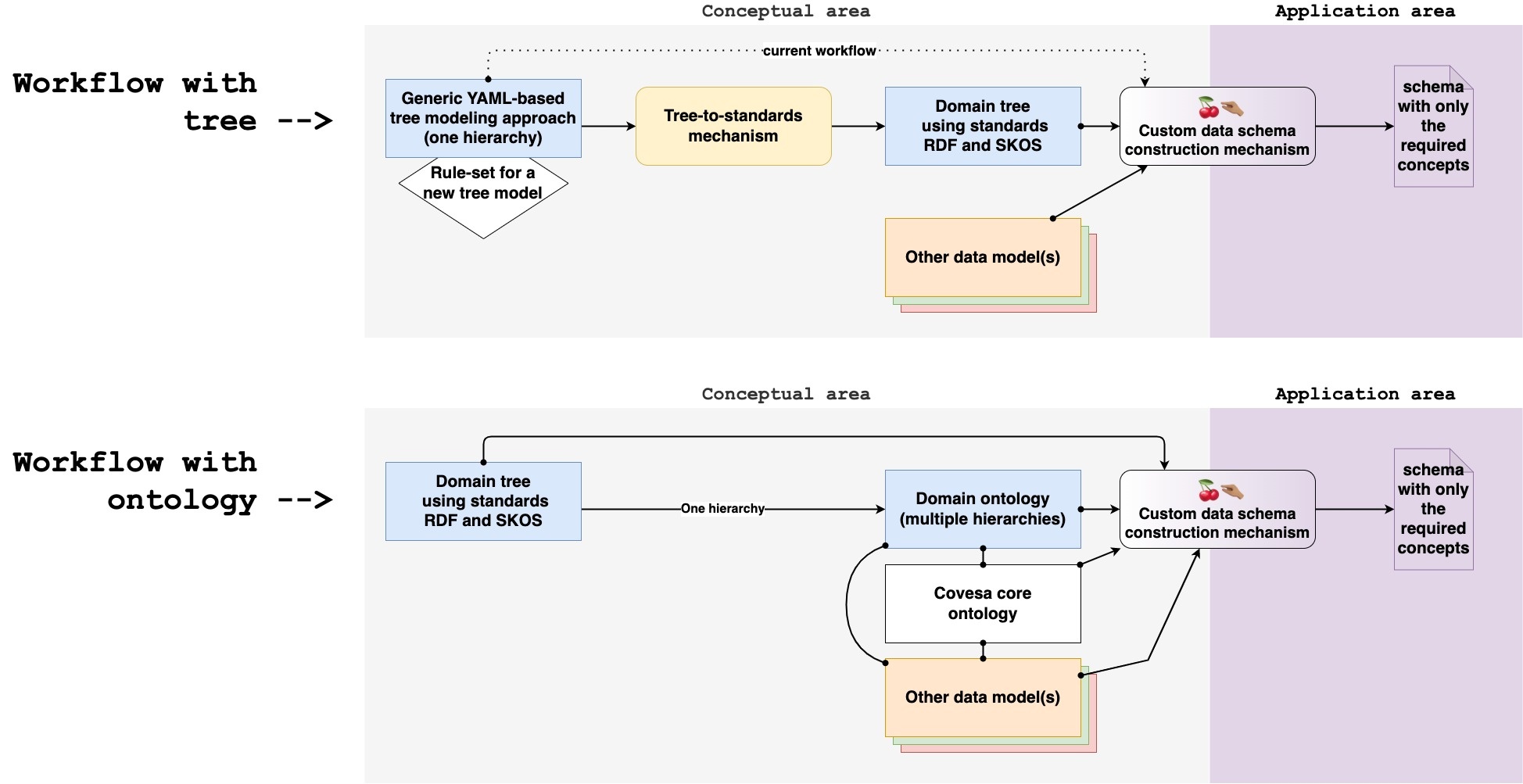
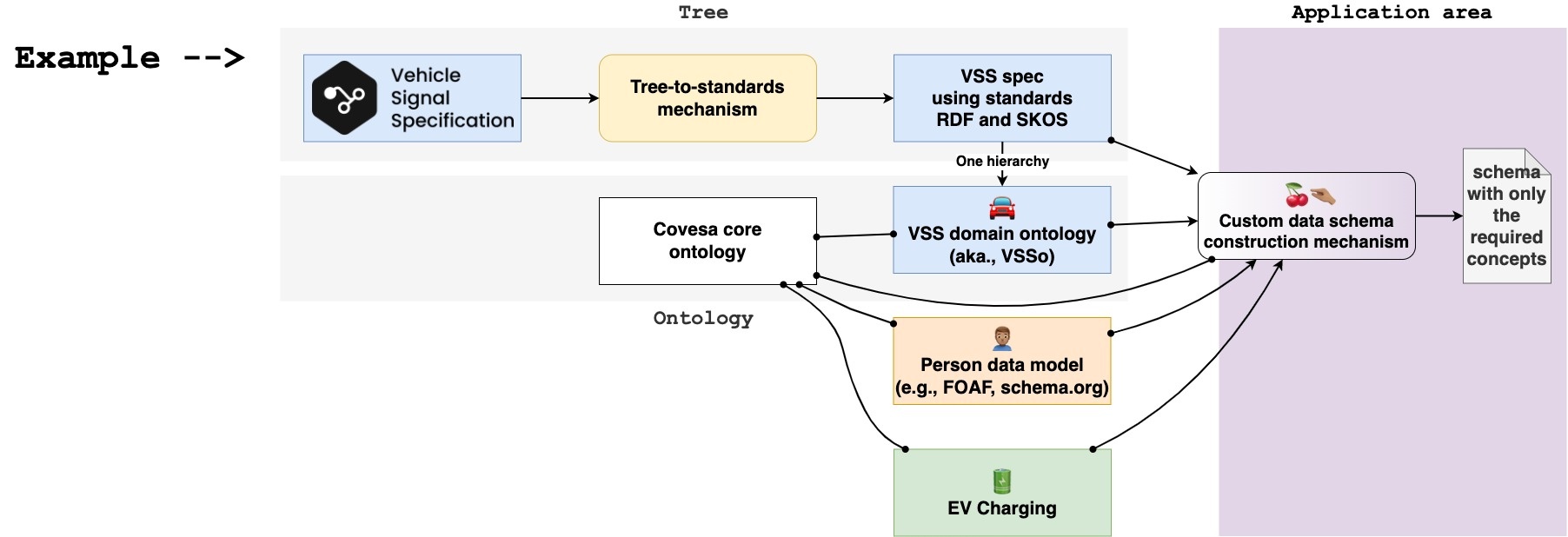
In other words, the proposal is not to enforce the use of ontologies. It is rather providing a common agreement on how and when to use what data model. The idea is better explained with the following figure, which is explained below:
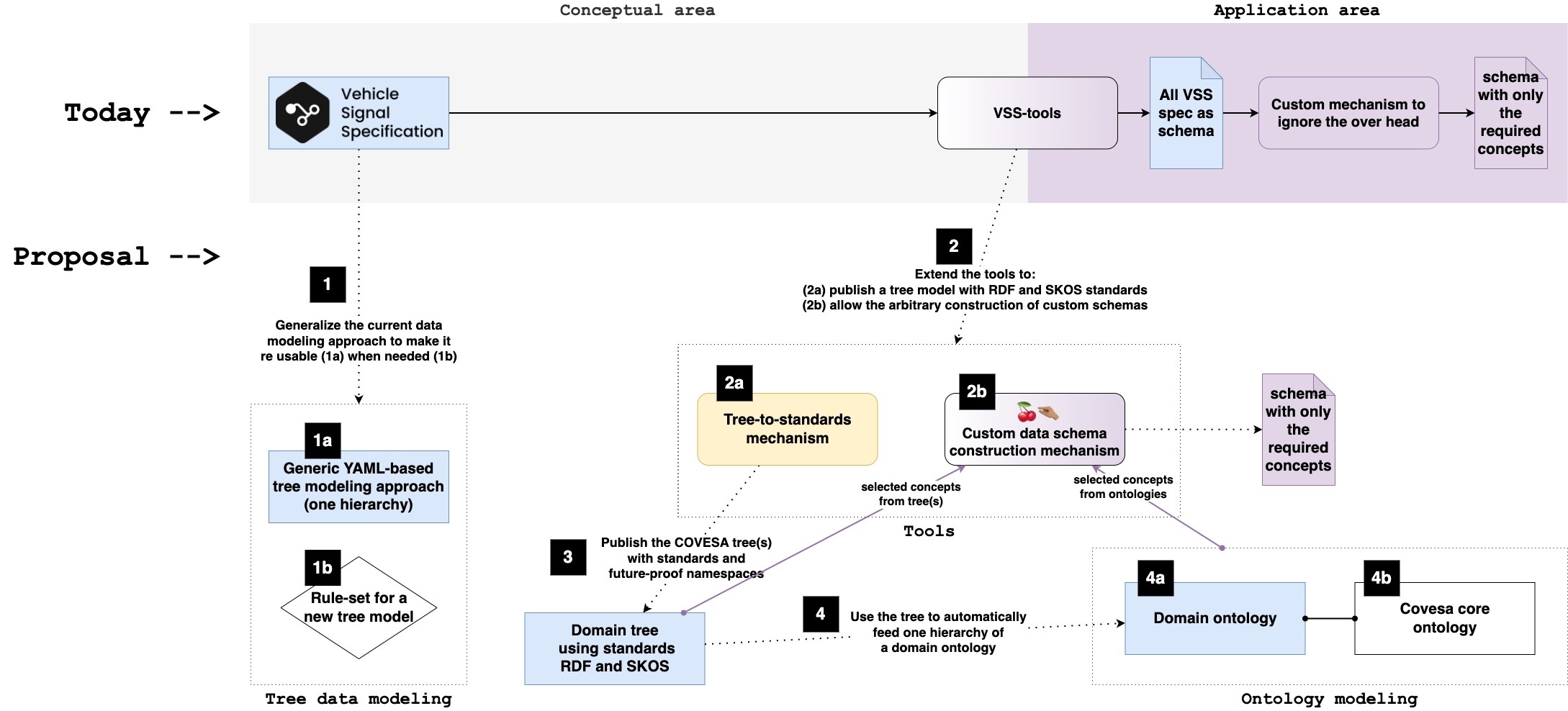
The simplicity of VSS has proven to be a successful approach for the continuous contribution of Subject Matter Experts (SMEs); just by modifying a text file, discussing the changes, and creating a pull request. The approach itself should be generalized to serve as a guideline to describe and maintain one hierarchy. The idea here is to abstract the modelling approach used in VSS and describe it with generic terms that might be re used with other domains. This implies doing some minor adjustments to geralize the YAML-based modeling approach, and also defining a rule set to support COVESA participants to identify the need of a new tree model.
People often refer to a hierarchical tree data model as a taxonomy. However, this is not always the case. Depending of the meaning of the implicit relationship between branches of a tree, the hierarchy can be:
Tree hierarchy type | Implicit relationship | Example |
|---|---|---|
ChildBranch -- Sub class of --> ParentBranch |
| |
ChildBranch -- Part of --> ParentBranch |
| |
Custom | ChildBranch -- Custom --> ParentBranch | VSS |
To handle these semantic differences, the following tasks are proposed:
Add a field at the beginning of the tree specification to explicitly state the tree type
# To include at the top of the spec YAML file (the root branch)
tree type as one of ['TAXONOMY','meronomy','CUSTOM']
Extend the tools to interpret the tree type as follows
Tree type | Tools will consider... | If custom relationship is needed... |
|---|---|---|
TAXONOMY | the "SubClassOf" as the default implicit relationship between branches | the user can define it within the branch definition. |
meronomy | the "PartOf" as the default implicit relationship between branches | the user can define it within the branch definition. |
CUSTOM | that no default implicit relationship exist. | in this case, it will be mandatory for all branches in the specification |
Add a field in the branch definition to explicitly state the implicit relationship to the parent branch
# Example of a branch that has a custom relationship
PowerTrain.Charging:
type: branch
description: Properties related to battery charging.
relationToParentBranch: 'functionOfVehicleComponent'
Having an stablished approach to model a tree hierarchy does not mean that COVESA should motivate the arbitrary creation of multiple trees. Data modeling is a continuous design task that requires several iterations and a huge maintenance effort. Therefore, it is essential to define a simple set of rules that are to be satisfied before starting a new data tree that is to be developed and maintained by COVESA. Such a rule set can include, for example:
Tools should be extended to use standards for the specification itself, and also to be able to arbitrarily construct the desired schema.
Current VSS-tools allow parsing the specification into multiple formats. The specification itself is done in the custom YAML file (i.e., with the vspec format). This is not an standard data exchange format. It is a good practice to specify taxonomies (and similar hierarchies) using standard formats [R1]. Two important reasons for that are interoperability, and re use of existing tools for editing and visualising the data models.
Here, the most prominent standards that are preferred today for these taxonomy-like data models are the Resource Description Framework (RDF), and the Simple Knowledge Organization System (SKOS).
The idea here is that a data model can contain much more concepts that the application area needs. This is because the application area might consist of multiple use cases. In principle, the idea here is to keep to the number of data models to maintain by COVESA to the minimum. Hence, a mechanism to construct custom schemas will decouple the need for the modification of the model.
Right now, the specification has a practical use after applying the vss-tools. The main identifier of a concept of interest (i.e., a tree leaf) is either the path defined with a dotted notation, or the UUID introduced recently. None of them is fully solving the identification of the resource.
The paths require a custom script that interpret them in other to do the mapping, whereas the current UUID approach does not guarantee that the identifier will remain unchanged when the path changes (e.g., a branch name change will lead to a different UUID).
The idea here is to take advantage of the principles of the RDF, which is the identification of resource in the web. For that, one must define a so called name space that will act as the address where the model is stored (hopefully forever). For example:
@prefix vss: http://covesa.global/datamodels/vss# .
This is the entry point for ontologies. The main limitation of a tree is that it can only handle one hierarchy. In the real world, however, the knowledge looks more like a semantic network than a simple tree.
We can take the advantage of a well-maintained tree to further enrich the vehicle data model. For example, a domain ontology can be useful for:
Once multiple models are involved, we must keep them inter operable. That means that we need to also have a controlled vocabulary to categorise new concept of interest into abstract and generic categories. For example
The systematic use of these controlled vocabularies will lead to an easy data integration.
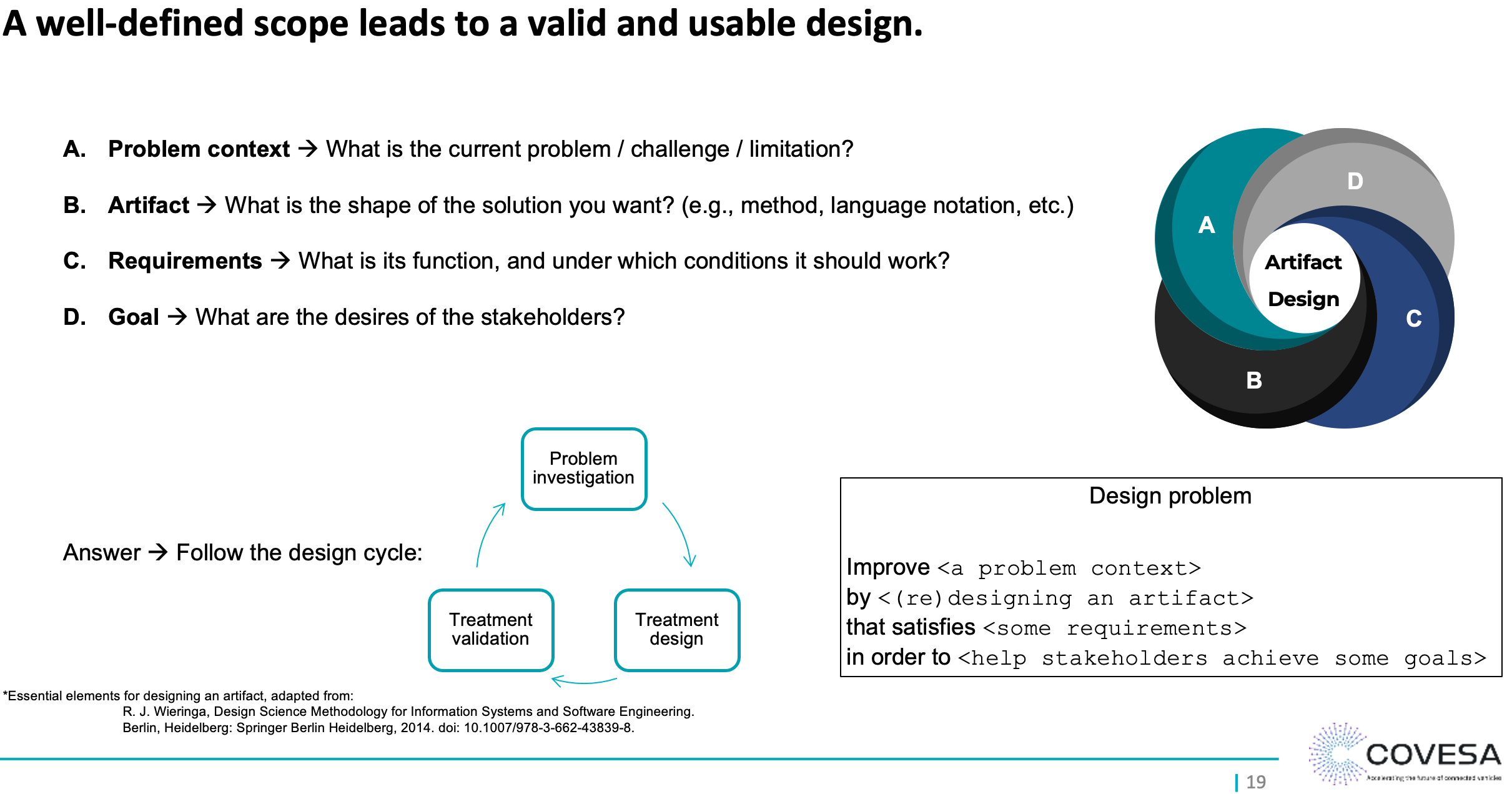
Designing an artifact that solves a problem can lead to multiple valid solutions. Therefore, a simple and clear methodology to guarantee the validity of the proposed solution must contain at least these 4 elements (adapted from [R3]):
2 Comments
Henkel Achim
I really appriciate the clear seperation of "conceptional area" and "application area". Nevertheless, I would appreciate to describe the interface between both worlds with a clear API (semantic+syntax) (e.g. in OpenAPI-style and/or json+Schema, or other open standards)
Daniel Alvarez
Thank you Henkel Achim for the comment. As you can see, I described the strategy in an abstract manner. That is exactly the point of opening this topic for discussion, so that we can collect the design principles for each artifact that is to be developed and maintained by COVESA.
You are referring to the mechanism between conceptual and application area (see number 2b.). To effectively design that mechanism, we must clearly define and agree on these 4 aspects:
For example, we can add the following information to shape the scope of that mechanism:
EXAMPLE: Design aspects for mechanism 2b